Video Abstract
Il rapporto tra l’Intelligenza Artificiale, le immagini e il linguaggio può essere visto alla luce di recenti teorie, che hanno un elevato influsso potenziale sull’arte.
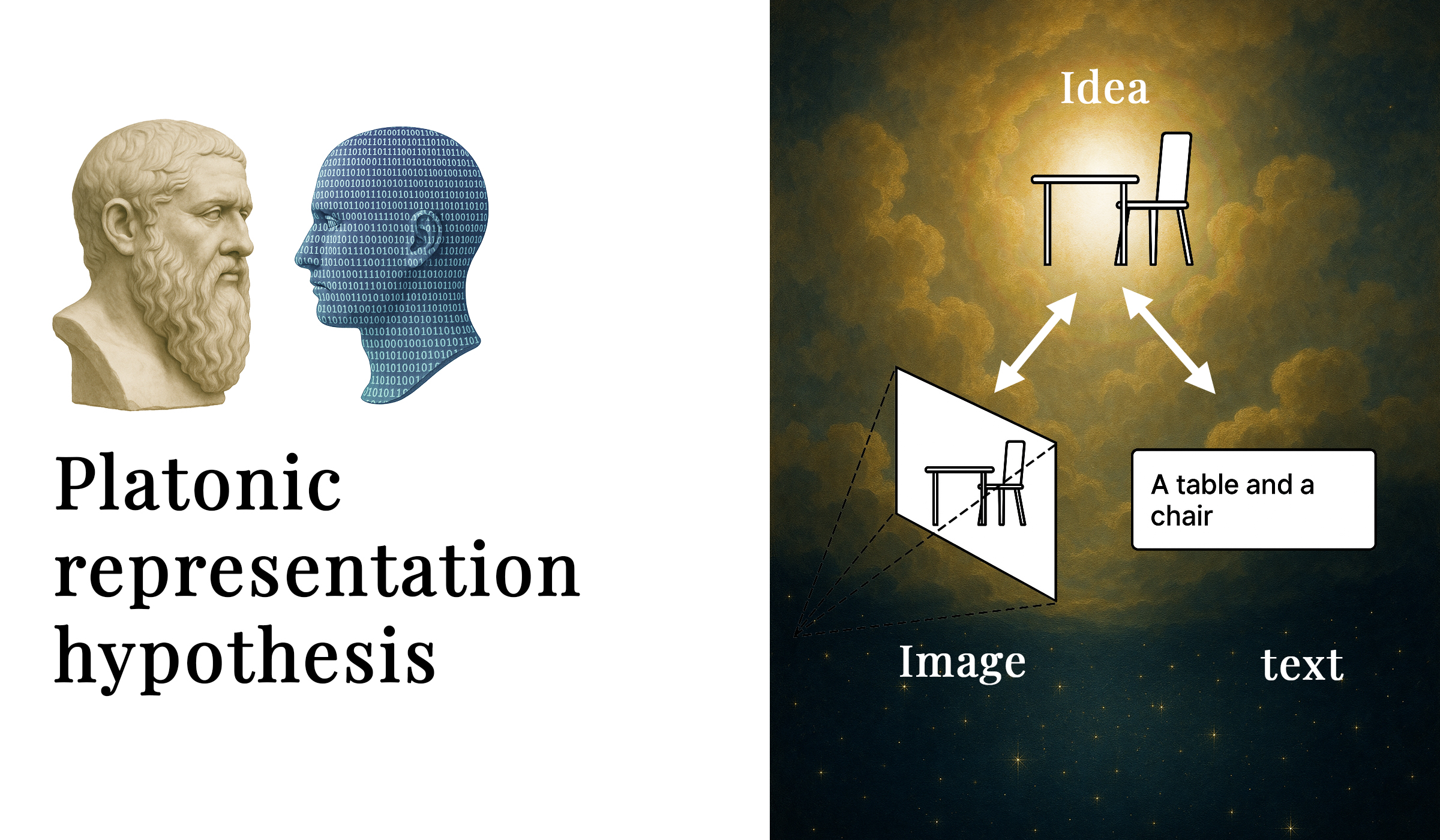
Secondo una ricerca pubblicata dal MIT di Boston – The Platonic Representation Hypotesis, di Minyoung Huh, Brian Cheung, Tongzhou Wang, Phillip Isola – i modelli linguistici di Intelligenza Artificiale stanno convergendo, creando modelli di rappresentazione dei dati sempre più uniformi.
Al di sotto delle moltissime lingue dell’umanità, oggi tradotte dall’Intelligenza Artificiale, ma anche delle immagini utilizzate dai modelli AI, si sta rilevando l’esistenza di una sorta di “mondo delle idee” universale, che richiama il concetto dell’iperuranio platonico.
Man mano che i modelli incontrano crescenti set di dati e applicazioni sempre più ampie, richiedono una rappresentazione che identifichi le proprietà fondamentali comuni, presenti in tutti i tipi di dati, siano essi testi o immagini.
L’ipotesi della rappresentazione platonica sostiene quindi che sia l’immagine (img) che il testo (text) sono proiezioni di una realtà comune sottostante, quella che Platone definiva “idea”.
Sembra quindi che nell’AI la visione e il testo stiano convergendo.
La visione artificiale, attraverso i sensori, acquisisce moltissime immagini di un oggetto del mondo reale. Le immagini rilevate dai sensori vengono classificate con una parola, ad esempio la figura geometrica di un cono, o una specie animale, il gatto, che a sua volta può essere espressa in più lingue (gatto, chat, cat…), ma mantiene il suo riferimento convergente alle immagini.
Questa rappresentazione ipotetica convergente viene definita “rappresentazione platonica” in riferimento all’Allegoria della caverna di Platone e alla sua idea di una realtà ideale che sta alla base delle nostre sensazioni. I dati di addestramento per i nostri algoritmi sarebbero quindi delle ombre proiettate sulla parete della caverna platonica. Partendo da questi dati rilevati, raccolti ed elaborati, i modelli stanno sviluppando rappresentazioni sempre migliori, e universali, del mondo reale che si trova al di fuori della caverna.
Aggiungiamo che, nelle reti neurali dell’AI, sono stati scoperti da Dravid dei “neuroni Rosetta” che fungono da ponte tra codificatori addestrati in diverse lingue, e vengono attivati dallo stesso schema in una gamma di modelli visivi. Tali neuroni formano un dizionario comune, scoperto in modo indipendente da tutti i modelli.
Man mano che i modelli di intelligenza artificiale crescono, grazie alla loro profondità e complessità, acquisiscono una maggiore capacità di astrazione. Questo permette loro di catturare concetti e modelli sottostanti i dati, eliminando rumore o valori anomali, e arrivando così a una rappresentazione più universale e potenzialmente più vicina al mondo reale.


 English
English